Chaitanya Mitash
Ph.D Student, Computer Science
Rutgers University
Chaitanya Mitash
Ph.D Student, Computer Science
Rutgers University
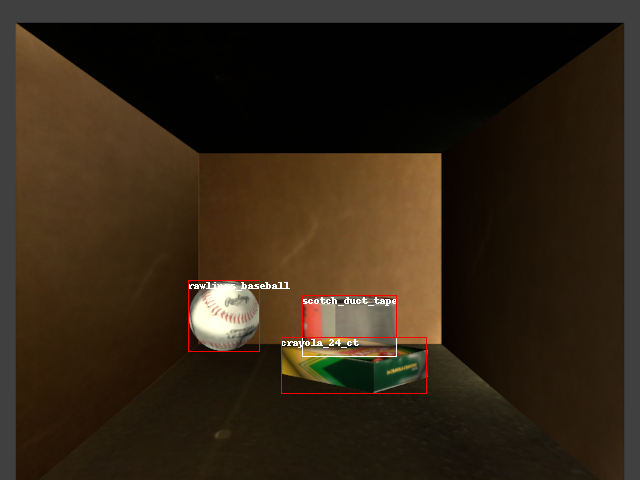
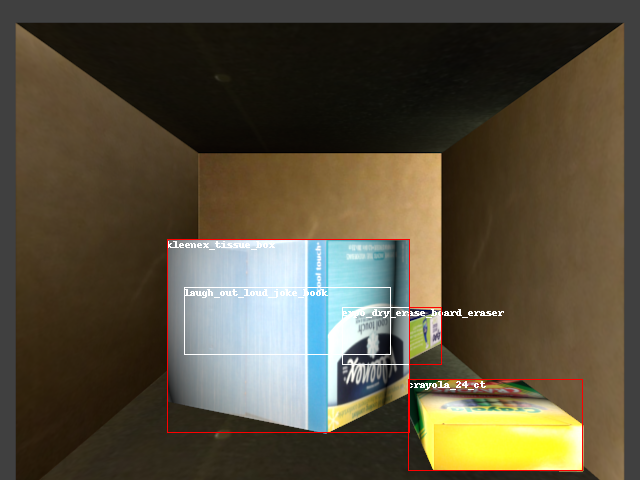
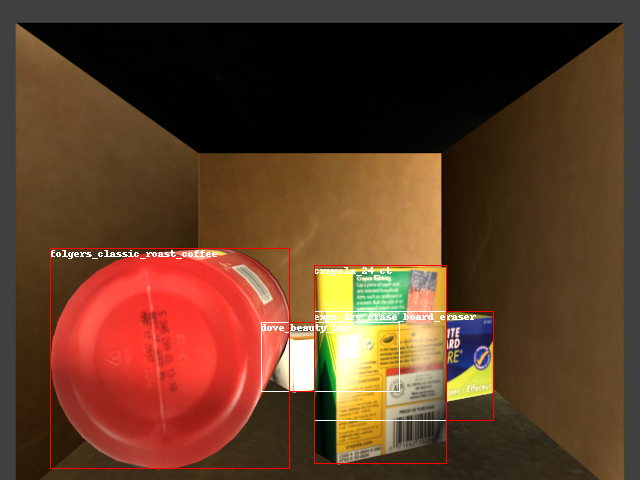
Abstract: — Progress has been achieved recently in object detection given advancements in deep learning. Nevertheless, such tools typically require a large amount of training data and significant manual effort to label objects. This limits their applicability in robotics, where solutions must scale to a large number of objects and variety of conditions. This work proposes an autonomous process for training a Convolutional Neural Network (CNN) for object detection and pose estimation in robotic setups. The focus is on detecting objects placed in cluttered, tight environments, such as a shelf with multiple objects. In particular, given access to 3D object models, several aspects of the environment are physically simulated. The models are placed in physically realistic poses with respect to their environment to generate a labeled synthetic dataset. To further improve object detection, the network self-trains over real images that are labeled using a robust multi-view pose estimation process. The proposed training process is evaluated on several existing datasets and on a dataset collected for this paper with a Motoman robotic arm. Results show that the proposed approach outperforms popular training processes relying on synthetic - but not physically realistic - data and manual annotation. The key contributions are the incorporation of physical reasoning in the synthetic data generation process and the automation of the annotation process over real images.